Base de datos y recursos
Recursos regionalizados usando Twitter
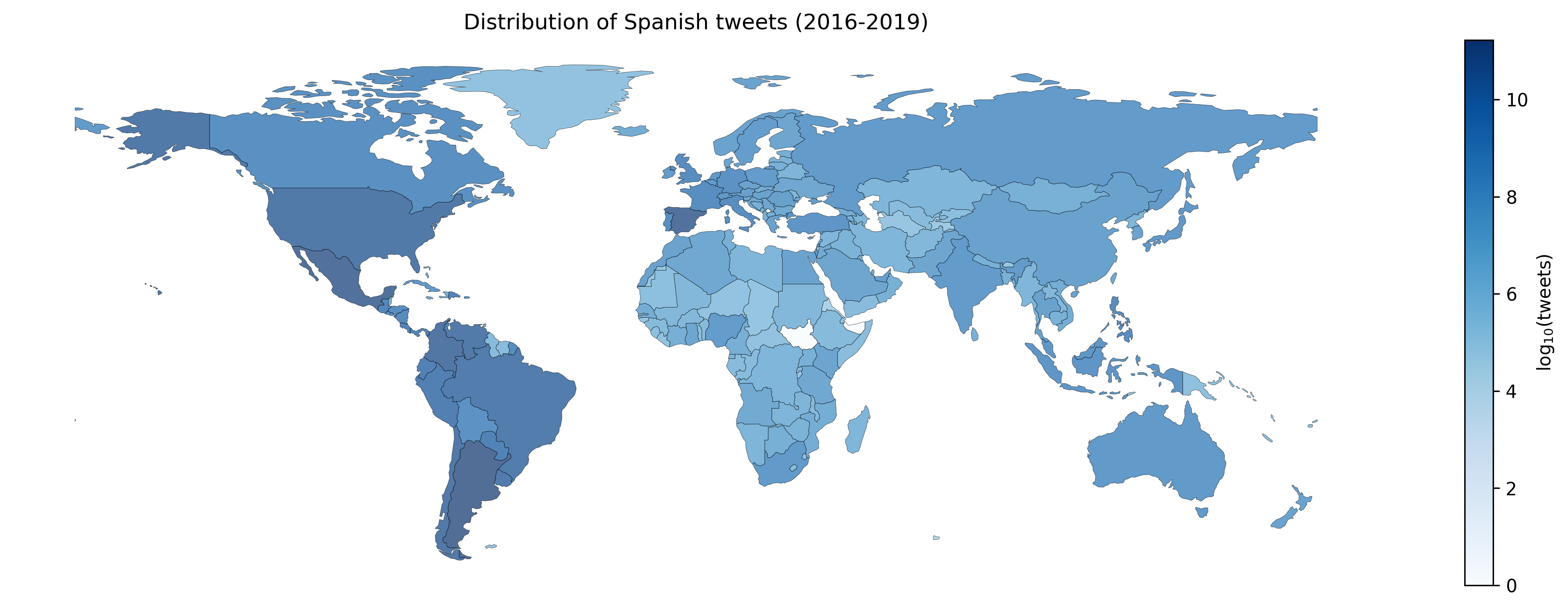
Tuits por región (es)
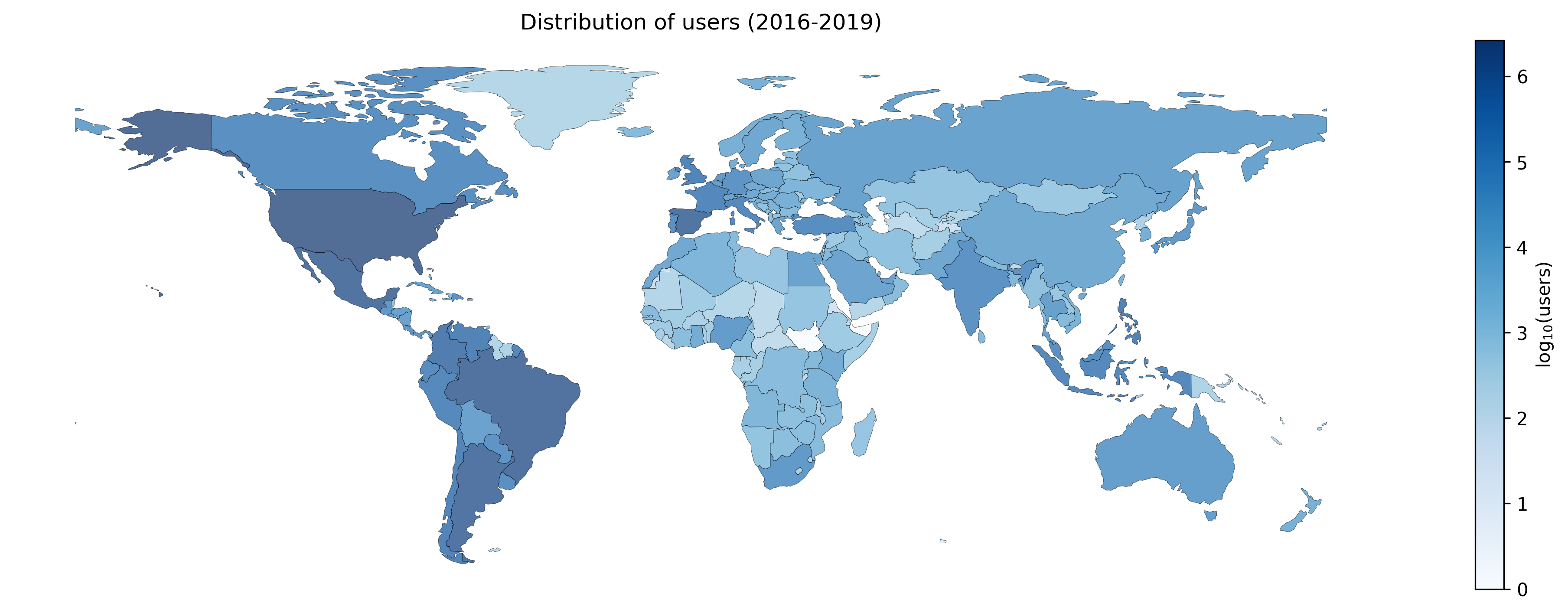
Usuarios por región (es)
Corpus
Se colectaron mensajes georeferenciados de 2016 a 2019 usando el API de stream público de Twitter.
| country | code | number of users | number of tweets | number of tokens |
|---|---|---|---|---|
| Argentina | AR | 1,376K | 234.22M | 2,887.92M |
| Bolivia | BO | 36K | 1.15M | 20.99M |
| Chile | CL | 415K | 45.29M | 719.24M |
| Colombia | CO | 701K | 61.54M | 918.51M |
| Costa Rica | CR | 79K | 7.51M | 101.67M |
| Cuba | CU | 32K | 0.37M | 6.30M |
| Dominican Republic | DO | 112K | 7.65M | 122.06M |
| Ecuador | EC | 207K | 13.76M | 226.03M |
| El Salvador | SV | 49K | 2.71M | 44.46M |
| Equatorial Guinea | GQ | 1K | 8.93K | 0.14M |
| Guatemala | GT | 74K | 5.22M | 75.79M |
| Honduras | HN | 35K | 2.14M | 31.26M |
| Mexico | MX | 1,517K | 115.53M | 1,635.69M |
| Nicaragua | NI | 35K | 3.34M | 42.47M |
| Panama | PA | 83K | 6.62M | 108.74M |
| Paraguay | PY | 106K | 10.28M | 141.75M |
| Peru | PE | 271K | 15.38M | 241.60M |
| Puerto Rico | PR | 18K | 0.58M | 7.64M |
| Spain | ES | 1,278K | 121.42M | 1,908.07M |
| Uruguay | UY | 157K | 30.83M | 351.81M |
| Venezuela | VE | 421K | 35.48M | 556.12M |
| - | - | - | - | - |
| Brazil | BR | 1,604K | 27.20M | 142.22M |
| Canada | CA | 149K | 1.55M | 21.58M |
| France | FR | 292K | 2.43M | 27.73M |
| Great Britain | GB | 380K | 2.68M | 34.62M |
| United States of America | US | 2,652K | 40.83M | 501.86M |
| Total | 12M | 795.74M | 10,876.25M |
Preprocesamiento
Solo se considera Twitter como fuente de datos. Los mensajes con URLs se descartan, lo mismo se hace con retweets y mensajes generados por aplicaciones (e.g., fourth square). Mensajes muy cortos también se descartan.
Los mensajes restantes se procesan como sigue:
minúsculas
se remueven las marcas de diacríticos
se agrupan hashtags, usuarios y números
números del se mantienen, el resto se representa como
se normalizan repeticiones de símbolos (max. 2)
las risas se normalizan (4 letras)
las cadenas de puntuaciones se cortan a 3 símbolos
Los tokens pueden ser palabras, puntuaciones o emojis.
Ley de Zipf
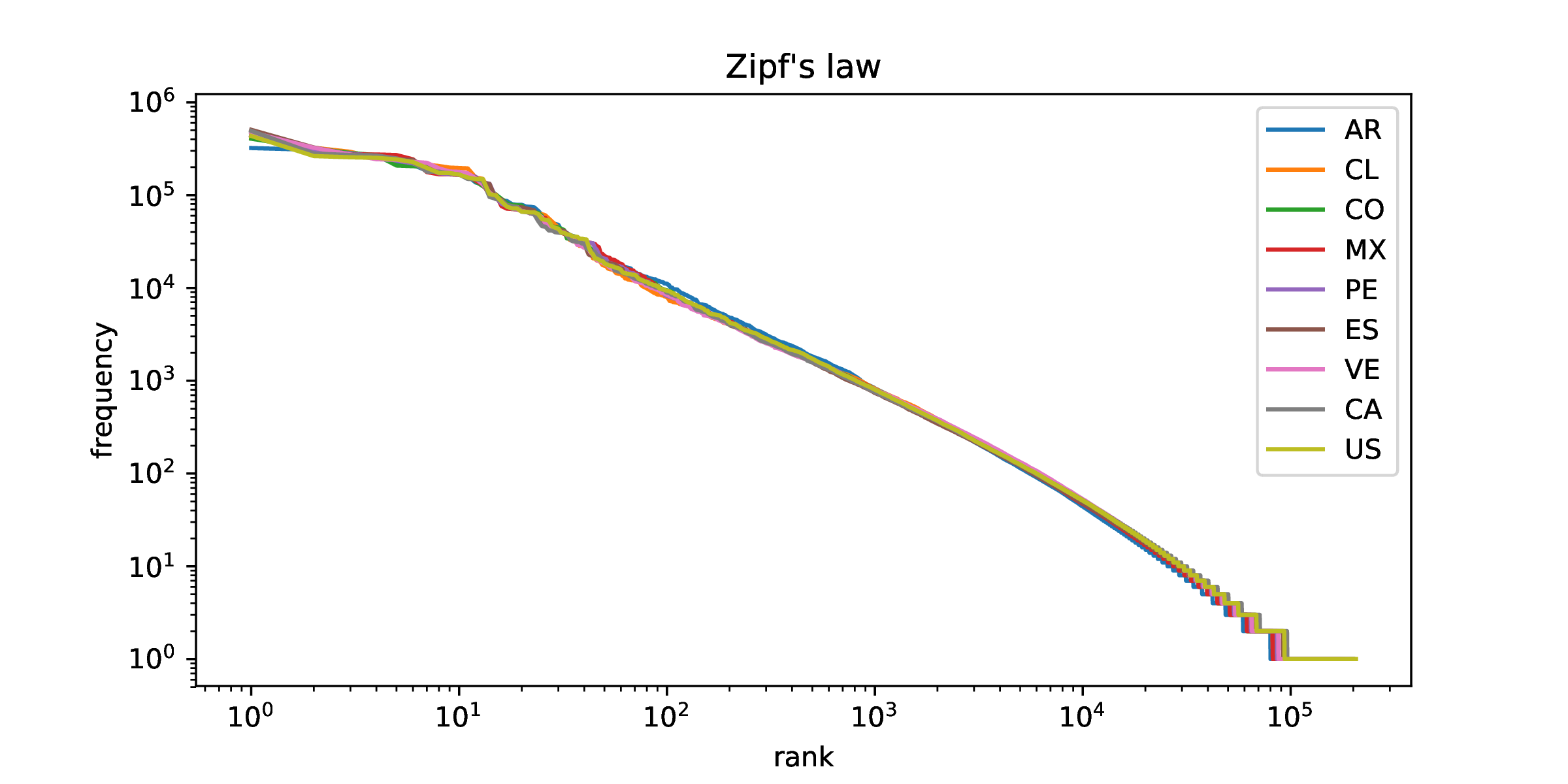
Ley de Zipf para diferentes regiones (Twitter)
Ley de Heaps
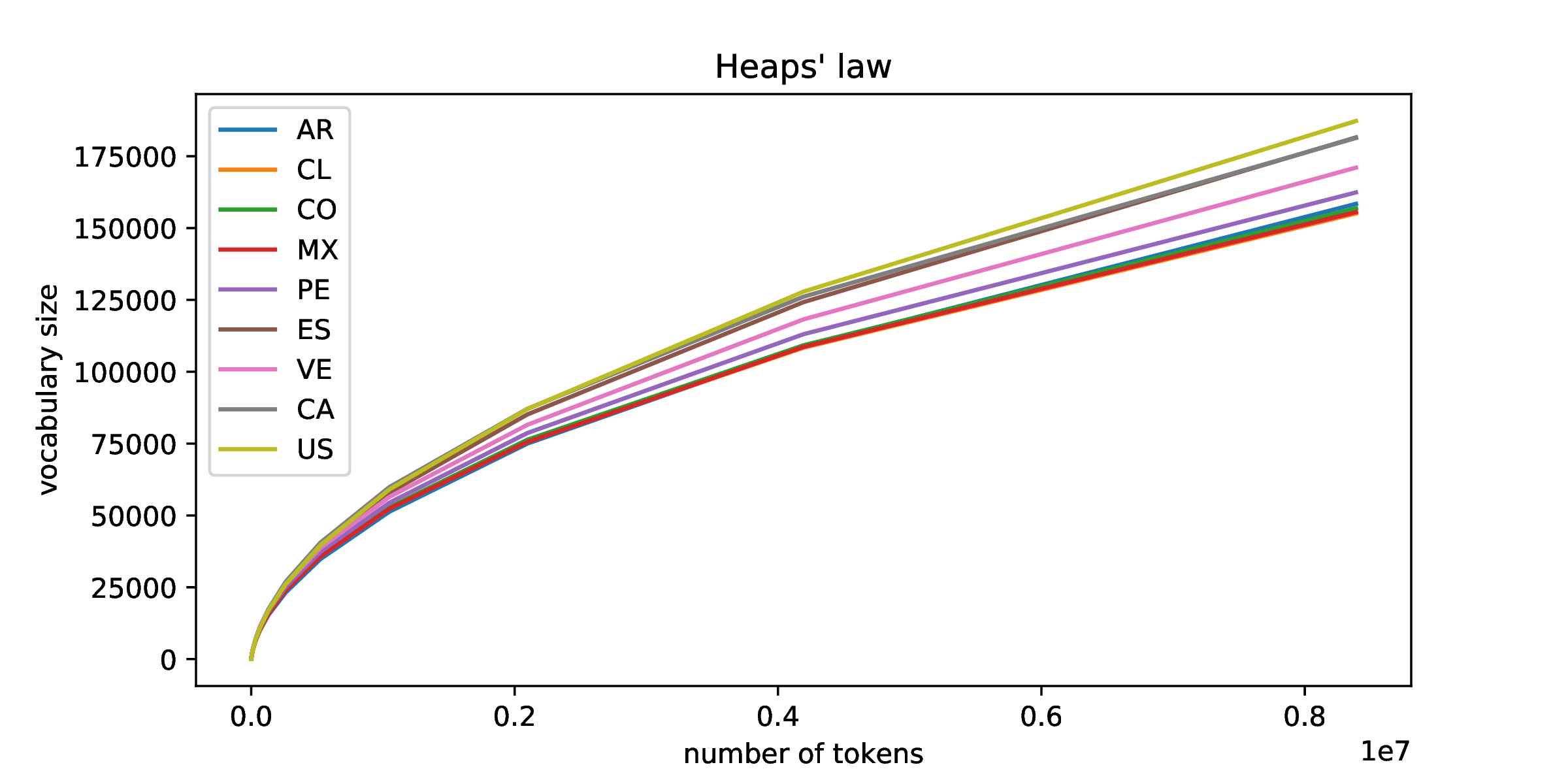
Ley de Heaps para diferentes regiones (Twitter)
CC BY-SA 4.0 Eric S. Tellez . Last modified: January 24, 2023.
Website built with Franklin.jl and the Julia programming language.